Our Technology
Open source. Any model. Fully yours to own.
MIT-licensed extraction engine, works with any AI provider through OpenRouter, and built to run on your infrastructure. Three products that cover the full document intelligence lifecycle. Public repository coming soon.
Works with any AI model. No vendor lock-in.
The Stack
Three products, one complete stack
From open-source extraction to a fully managed platform. Pick the tools that fit your stage.
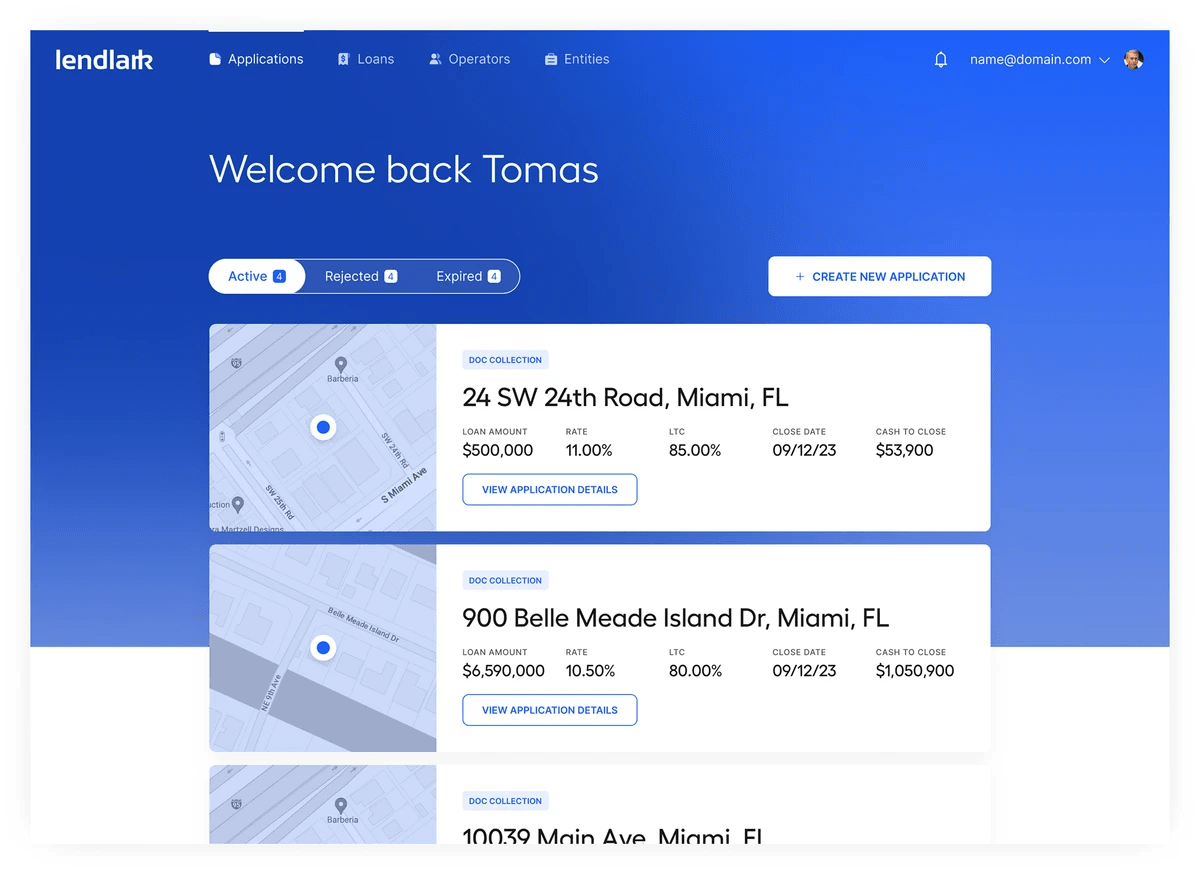
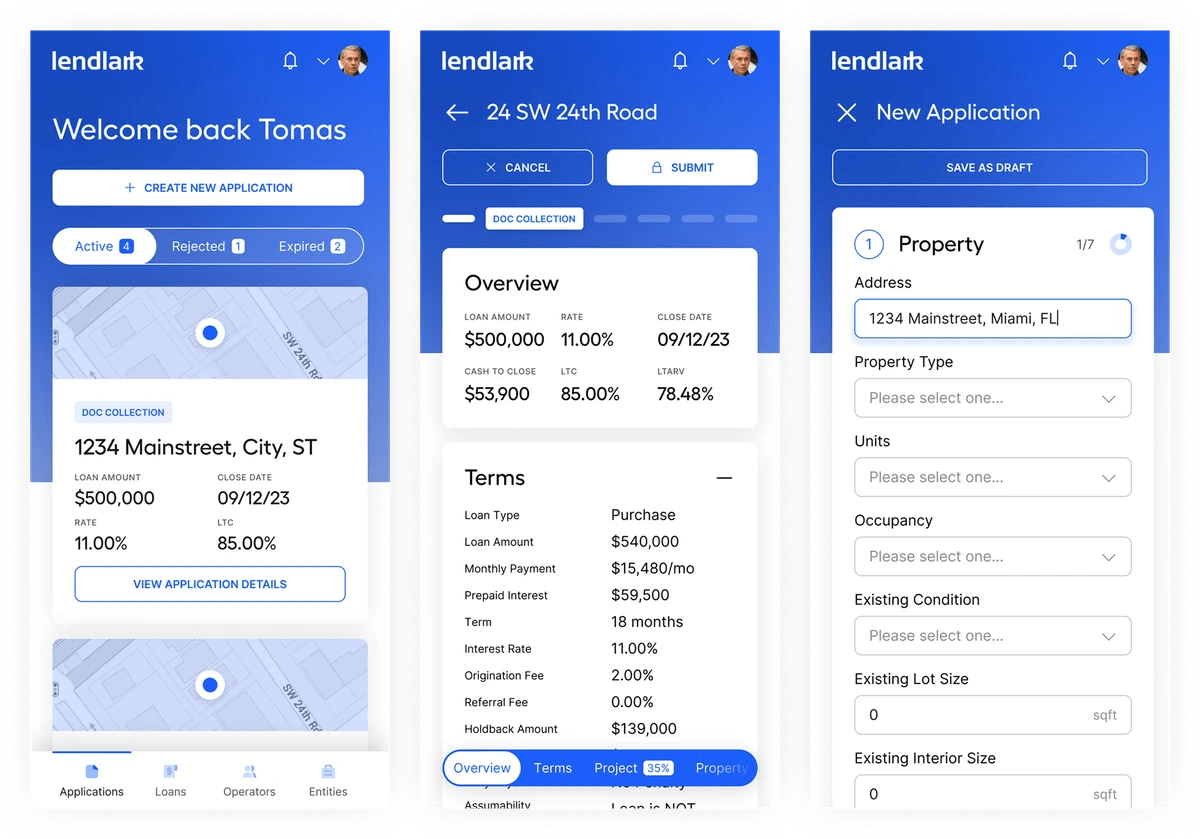
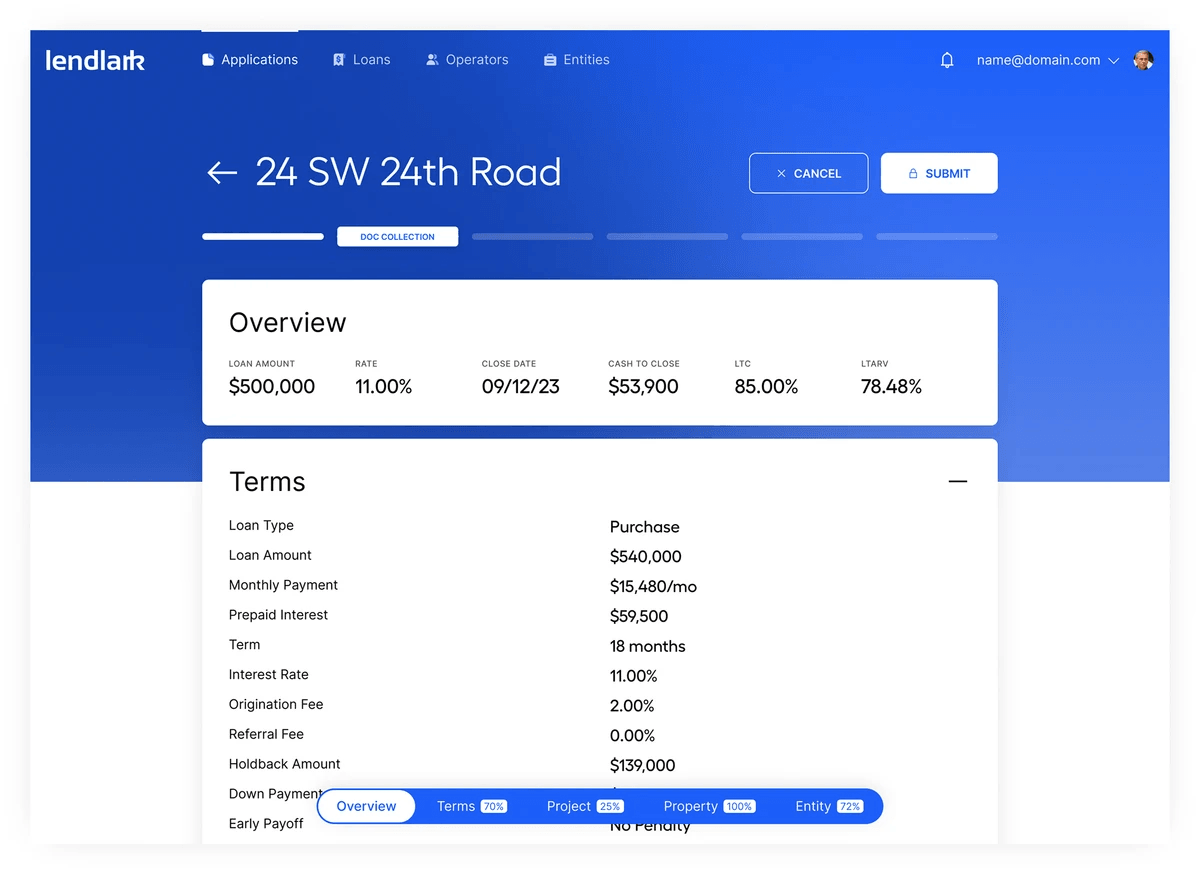
In Practice
Technology applied to real document challenges
See how organizations use the Doclo stack to automate document workflows at scale.

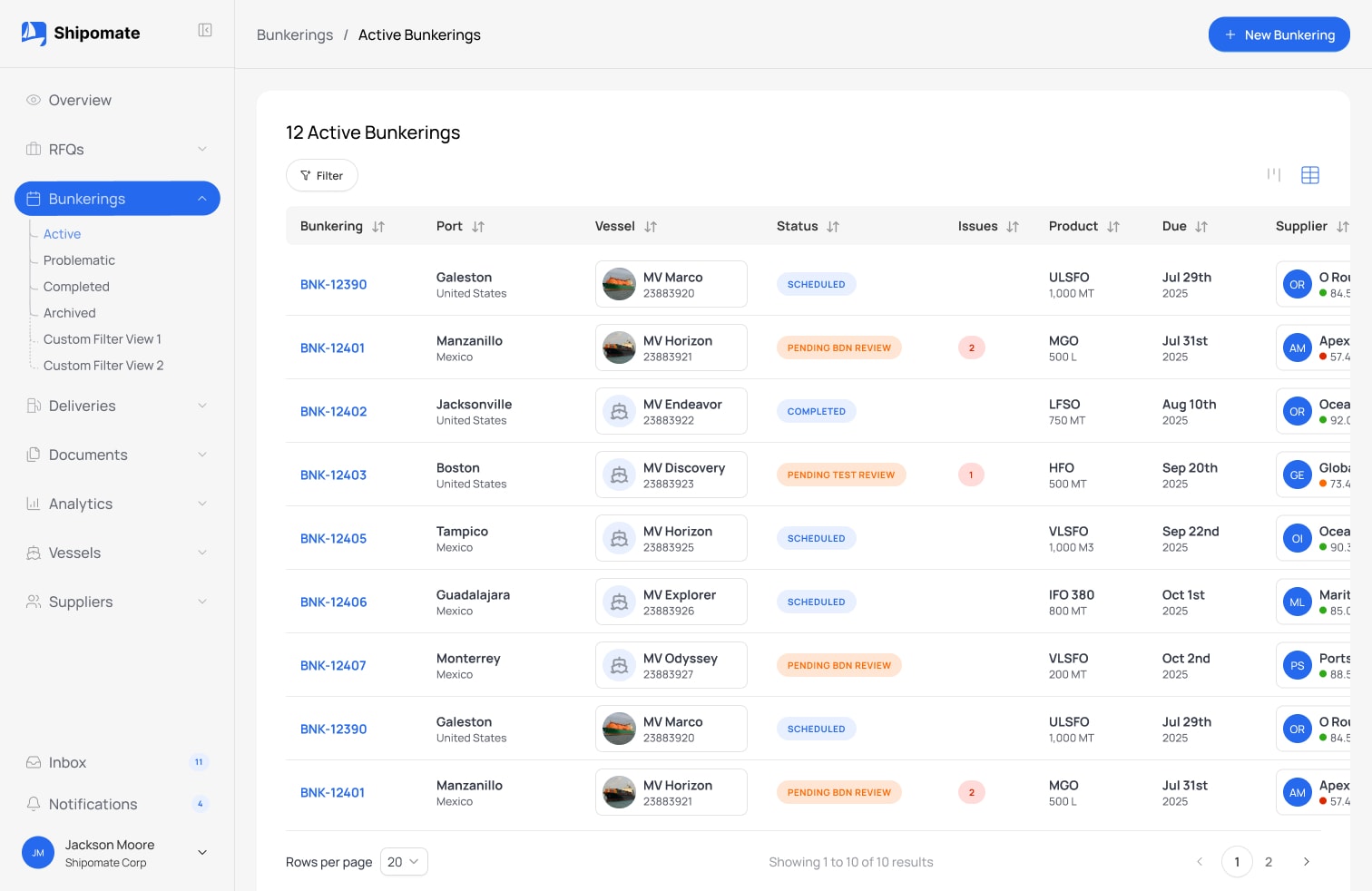
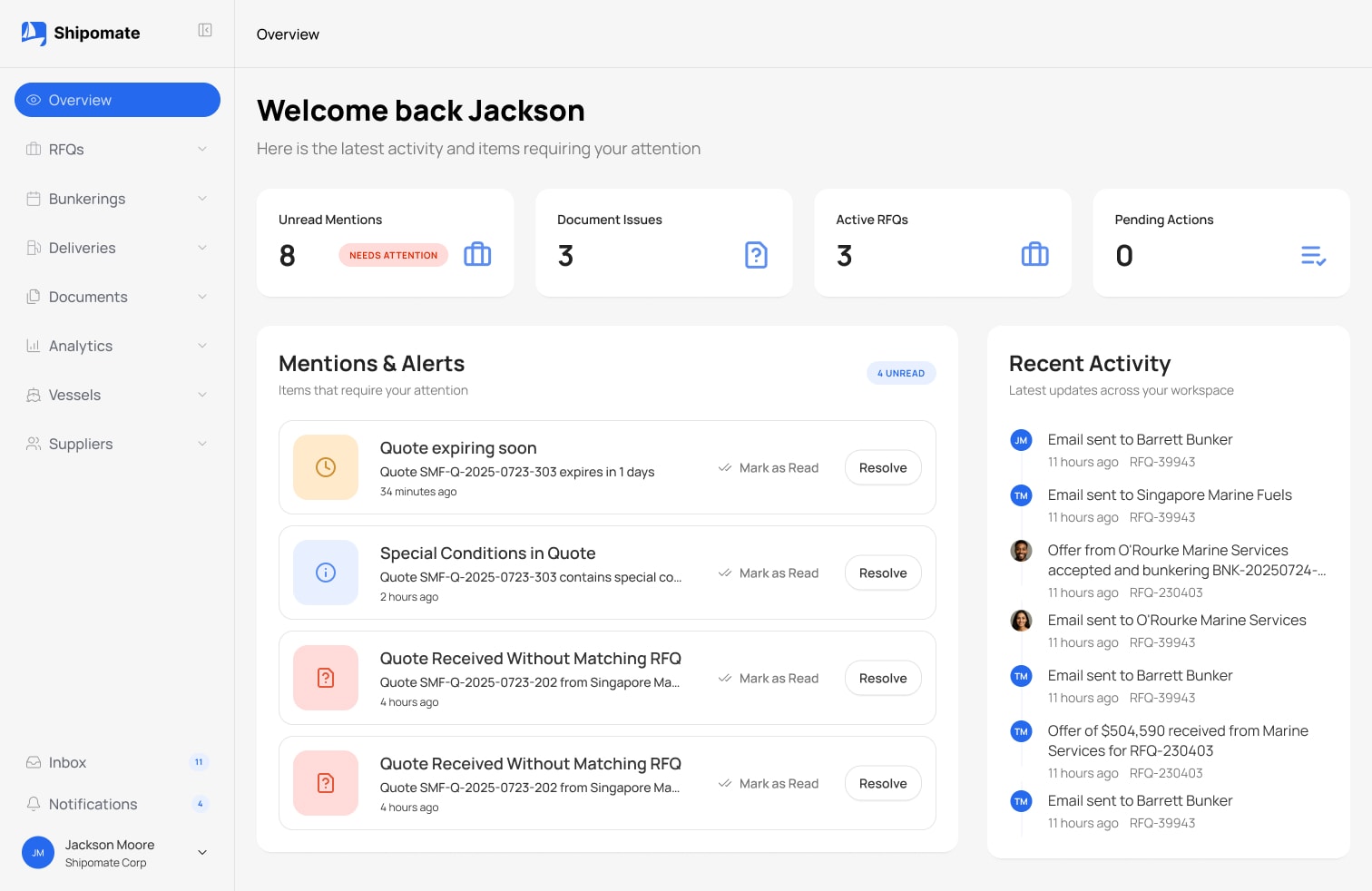
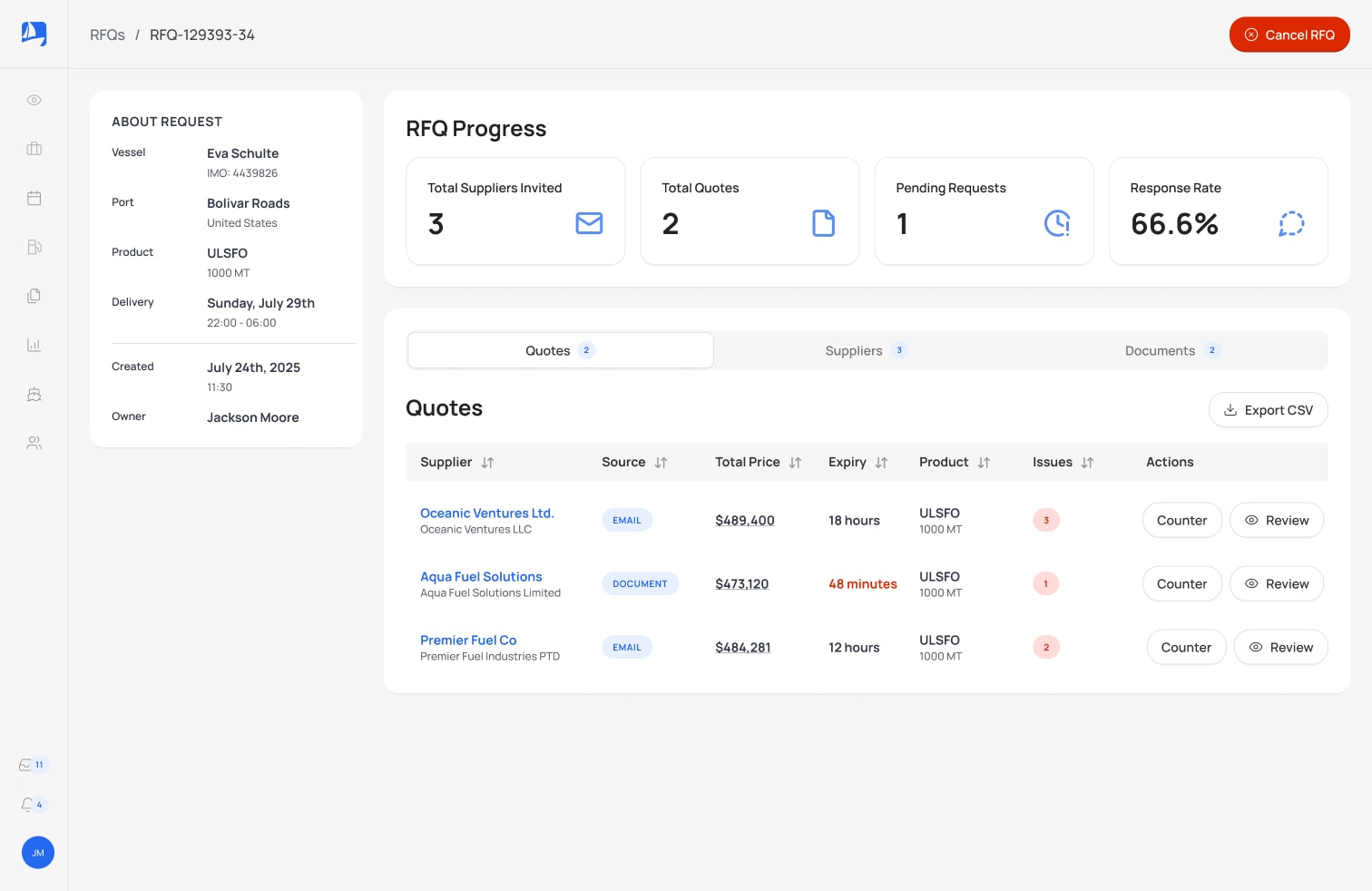
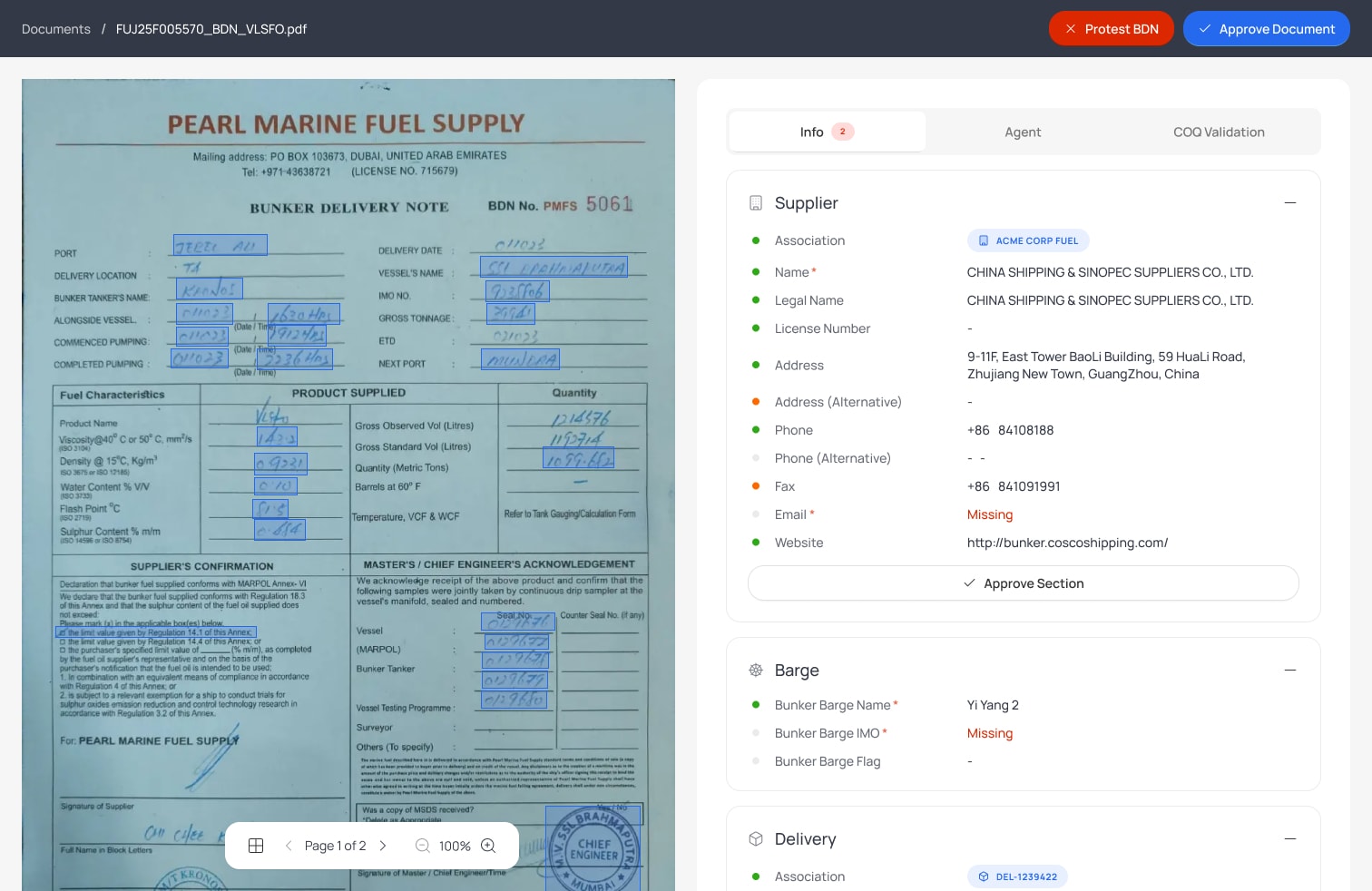
Open Source Engine
Unified document extraction, any provider, any model.
Self-hosted, MIT-licensed. Normalize multiple extraction providers behind one API. Vision-model first, deploy anywhere.
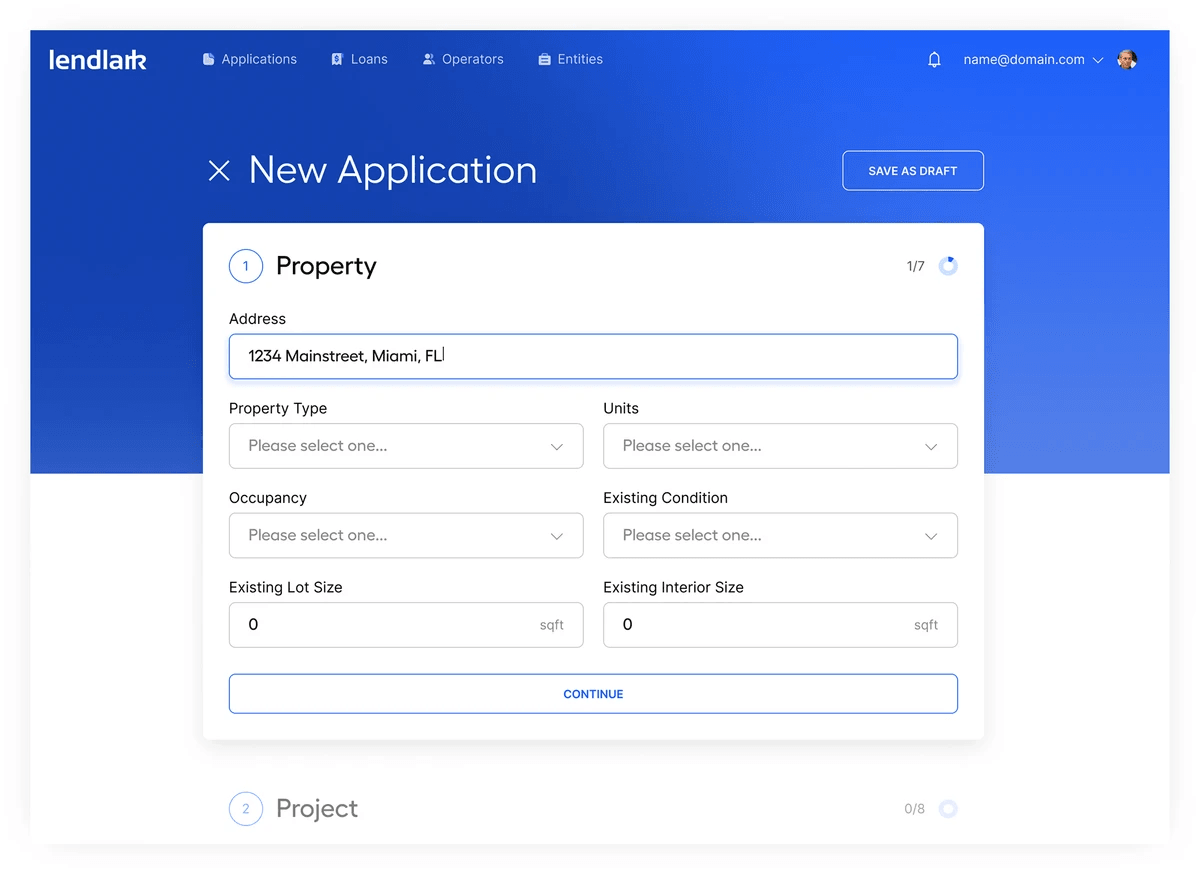
One consistent interface for any document extraction provider. Define your extraction schema once (JSON-based field definitions with types, validation rules, and output formats), and run it against any provider. Swap models without changing application code.
Not an OCR wrapper. The engine sends full page images to vision models for layout-aware understanding: multi-page documents, merged table cells, handwritten fields, and mixed-format pages. Plug in OpenAI, Anthropic, Google, open-source models, or your own fine-tuned models. We can help you host and fine-tune models tailored to your documents.
Fully open source. Audit, extend, contribute. Run on AWS, GCP, Azure, bare metal, or air-gapped environments. Structured output includes field-level confidence scores, bounding box coordinates, and extraction metadata for downstream validation.
Synthetic Documents
Source-truth documents for evals and training.
Generate realistic document variants to benchmark accuracy, train extraction models, and stress-test pipelines before they hit production.
Generate thousands of document variations with controlled degradation: variable fonts, scan noise, skew, resolution changes, and layout shifts. Output as PDF, TIFF, or image with pixel-perfect ground-truth labels for every field.
Compare provider performance on your specific document types with ground-truth labels you control.
Use synthetic data to augment training sets, reduce annotation costs, and validate pipeline reliability before production.
Custom Platform
Not one-size-fits-all. Built around your business.
We deliver a customized solution, managed or self-hosted, designed around your processes, documents, and goals. Our platform and infrastructure give you a head start. Then we tailor every detail to how your team actually works.
We take our platform and shape it around your document types, approval chains, compliance rules, and team structure. No generic tooling. A solution designed for your business.
Intelligent extraction, classification, and validation powered by the best AI models for your documents. Accuracy improves over time as the system learns your data.
Run on your cloud, on-premise, or let us manage everything. Full custom branding with your own domains and styling. Your data stays under your control.
Our guiding principles
Every product decision is guided by principles designed to ship reliable document intelligence.
Open by default
Our core engine is MIT-licensed. Audit, extend, and own it. No black boxes, no lock-in.
Infrastructure-first
Deploy on your cloud, your hardware, or air-gapped environments. Documents never leave your control.
Provider-agnostic
Use the best model for each task. Swap providers without changing code. No single point of failure.
Capabilities
Everything you need to process documents at scale
Four core capabilities that work together across all three products to power your workflows.
Extraction
Pull structured data from any visual source. Handwritten forms, PDFs with merged table cells, scanned blueprints, multi-page documents, and photos. Field-level confidence scores with bounding box coordinates for every extracted value.
Classification
Detect document type, assess quality, and determine next steps. Route to the right team or workflow automatically.
Multi-provider AI
Use OpenAI, Anthropic, Google, Mistral, or your own models. Swap anytime without code changes.
REST API
Connect via REST endpoints configured through Doclo's visual schema editor. Define extraction fields, set validation rules, and get full programmatic control over your document workflows.
Deployment
From repo to production
Our team handles deployment, integration with your existing systems, and ongoing optimization. You get a working solution, not a repository to figure out alone.
01
Assess
We audit your document workflows and identify the highest-impact automation opportunities.
02
Implement
We configure and deploy the stack for your specific documents and systems.
03
Optimize
We monitor, tune, and expand as your needs evolve. Ongoing partnership.
See it extract your documents.
Bring a sample document to a 30-minute call. We run it through our engine live and show you the structured output.
MIT
Licensed engine
Any
AI model
4–6 weeks
To production
Full
Data ownership