Meet Doclo
Build, evaluate, and optimize AI document workflows
Doclo's eval-first approach ensures your AI document workflows are accurate, reliable, and continuously improving.
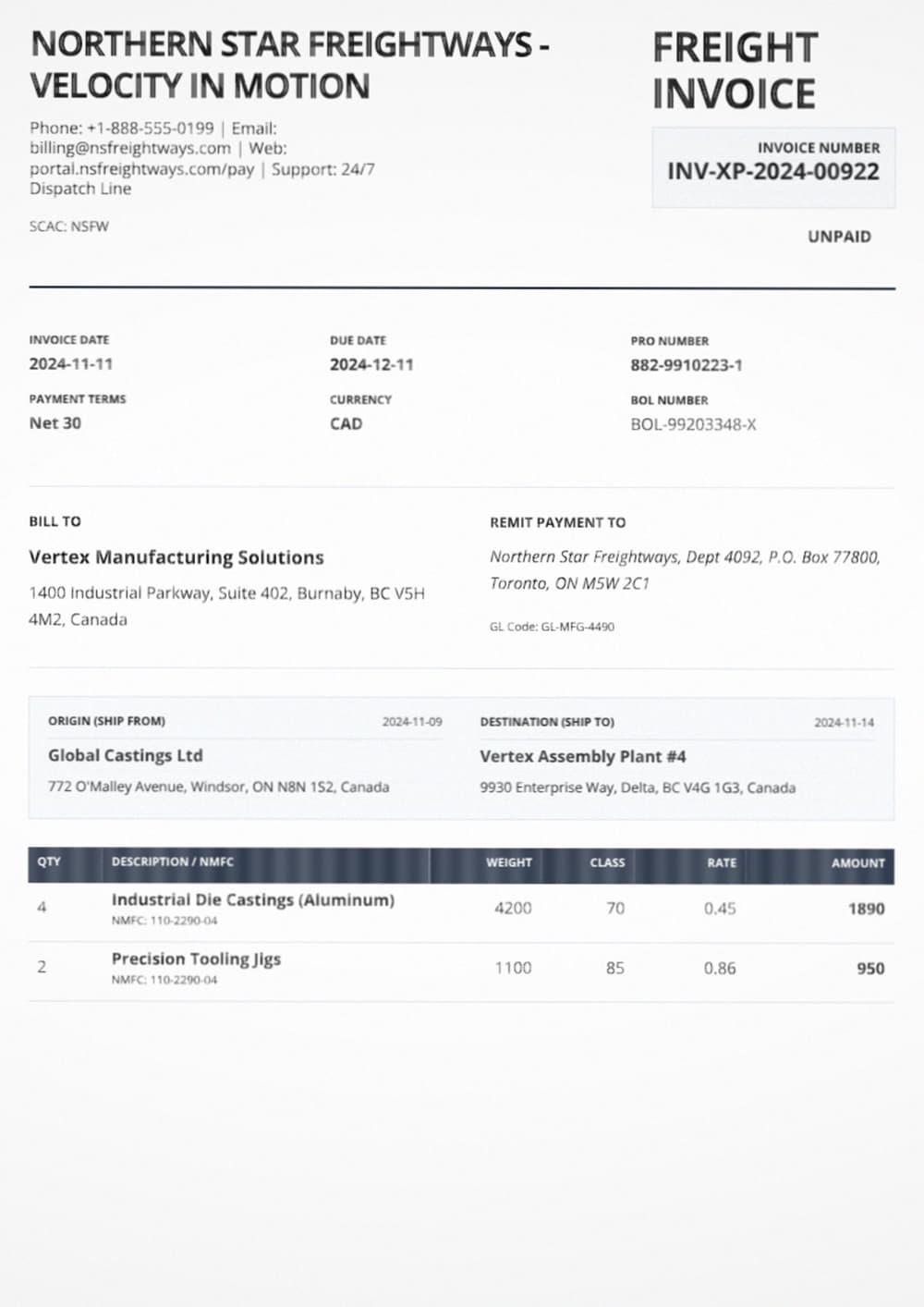
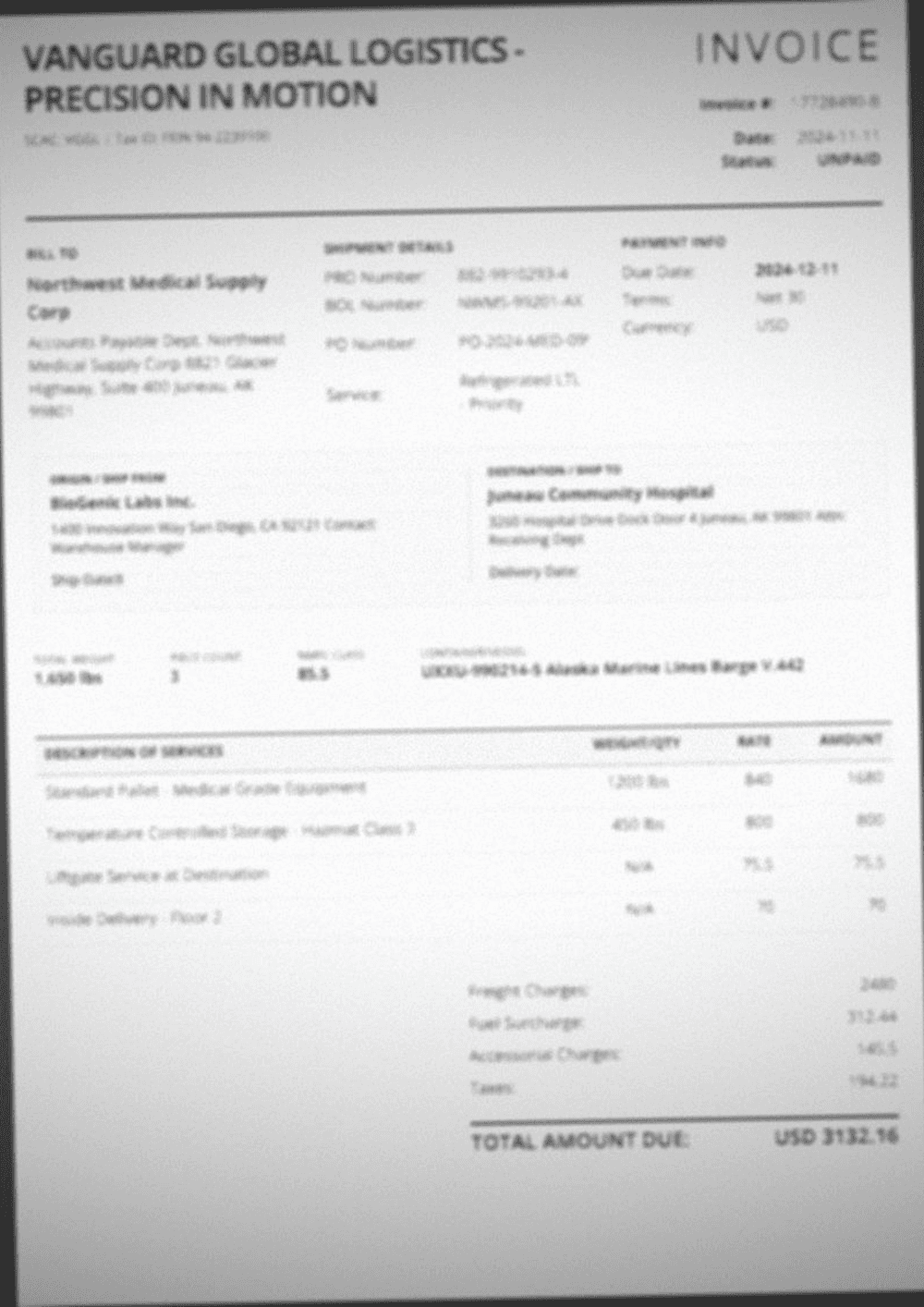
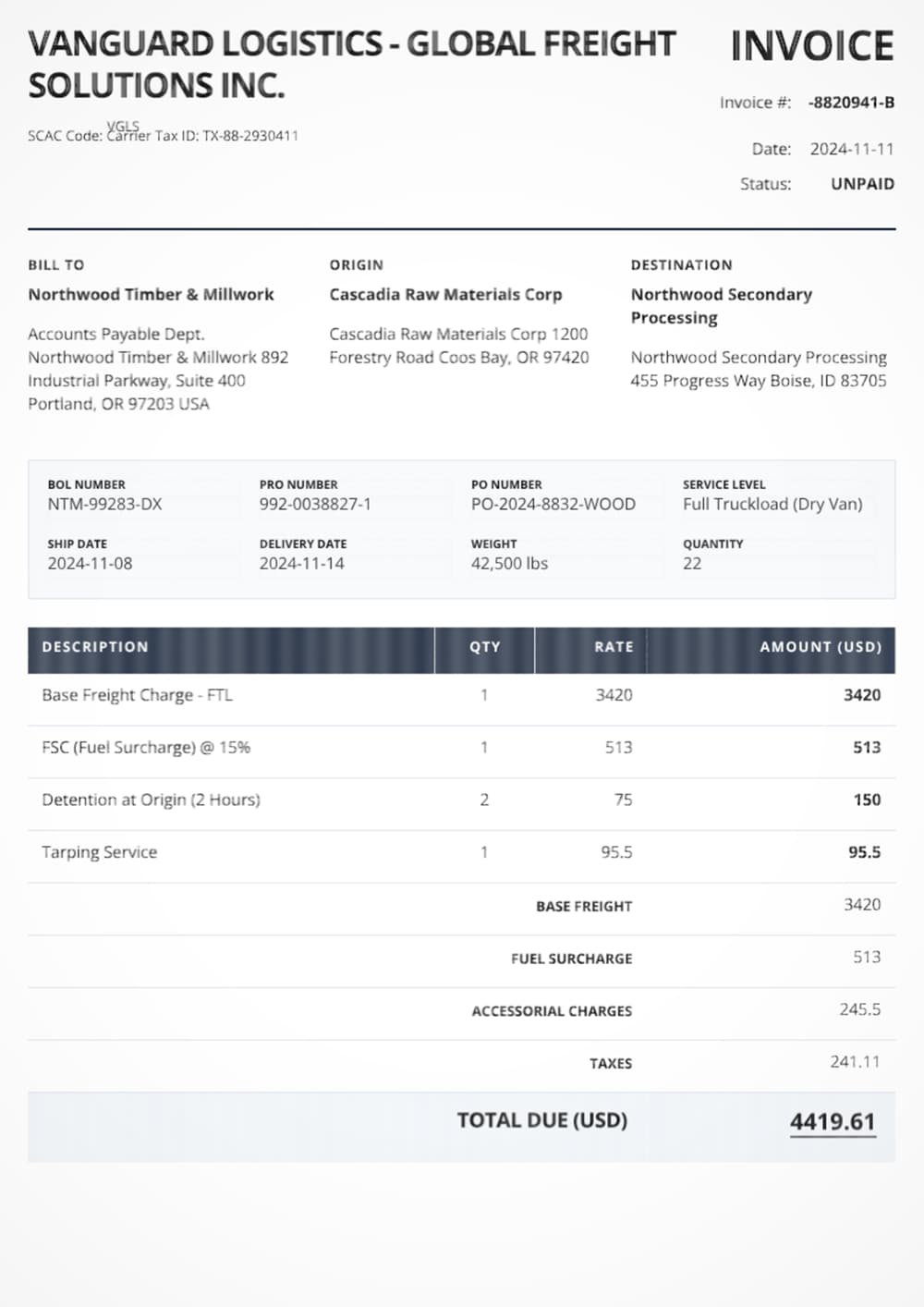

Create a logistics flow for BOLs, invoices, and damage claims. Use parse + extract for damage claims.
I'll set up the full workflow with schemas and routing.
Done! BOLs and invoices route to direct extraction, damage claims go through parse + extract. Ready to test.
Build
Build multi-step, multi-provider workflows visually
Chain together Parse, Extract, Categorize, and Split nodes across different AI providers. Configure each step independently, test the full pipeline, and publish when ready.
Evaluate
Generate realistic synthetic documents with ground truth
Generate realistic test documents with ground truth in minutes instead of weeks of manual labeling. No sensitive customer data needed. Run evals across models and prompts with a consistent test set, and catch regressions including rare edge cases before you ship.
Optimize
Move quickly with the built-in Doclo optimizer agent
The Doclo agent helps you build new workflows, generate test cases, update extraction schemas, and evaluate performance across providers. Tell it what you need and it handles the rest.
Create a logistics flow for BOLs, invoices, and damage claims. Use parse + extract for damage claims.
I'll set up the full workflow with schemas and routing.
Done! BOLs and invoices route to direct extraction, damage claims go through parse + extract. Ready to test.
Platform
Everything you need to ship document AI
Build workflows visually, test against ground truth, monitor in production. All in one platform.
Get in TouchVisual Flow Builder
Drag-and-drop pipeline creation. Parse, Extract, Categorize, Split, Trigger nodes. Version control with publish/draft workflows. No YAML, no config files.
Interactive Playground
Upload a document, run your flow, inspect every step. See exactly what the model extracted, where it came from, and what it cost.
Built-in Evaluations
Run test suites across flow versions with field-level accuracy tracking. Generate synthetic test documents at scale without building large ground truth datasets manually.
Real-Time Analytics
Execution counts, success rates, latency percentiles, cost breakdowns. Filter by time range, flow, or provider. See what's happening right now.
Alerting & Notifications
Set thresholds for error rates, latency, and costs. Get notified before problems become outages. Webhooks for your existing incident tools.
Schemas & Prompts
Reusable extraction schemas with validation. Versioned prompt templates. Track which flows use which assets. Change once, update everywhere.
Use Cases
From PDF to production data
Invoice Extraction Pipeline
Parse invoices, extract vendor details, line items, and totals with field-level accuracy tracking and cost transparency.
Doclo Cloud
Doclo SDK
const flow = createFlow()
.step('categorize', categorize({
provider,
categories: ['Standard', 'Medical',
'Legal']
}))
.conditional('extract', (ctx) => {
const schema = schemas[ctx.category];\n return extract({ provider, schema });
})
.build(); Reducto
ReductoIntegrations
Any model. Any provider. Zero lock-in.
Switch between AI providers and OCR engines with a single click. No rewrites, no migration headaches. Your workflows stay the same.
Collaboration
Built for teams that ship
Invite your team, manage permissions, and track costs. All plans include the tools you need to collaborate.
Team Management
Multi-organization support. Invite teammates with Owner, Editor, or Viewer roles. Workspace isolation keeps projects separate.
Security & Compliance
Encrypted credential storage. Secure document proxy with no raw URLs exposed. Comprehensive audit logging. Variety of ZDR options available.
API Access
REST API for programmatic execution. Scoped API keys with granular permissions. Idempotency support for safe retries. Webhooks for async processing.
Cost Transparency
Per-document and per-field cost tracking in USD. See exactly what each extraction costs. No surprise bills at the end of the month.
Cloud gives you visual workflow builder, managed infrastructure, analytics, and team features. SDK gives you full programmatic control in your environment. Same engine underneath. Start with one, switch later.
Get Started
Ship production document AI this week
Get in touch and let's discuss your project and needs.